Large Language Models (LLM) open up many opportunities for how humans interact with recommender systems. In particular, I’m interested in “Aspirational Recommendation” in which a human can specify a personal goal (e.g., “I want to listen to more local music.”) and recieve relevant recommendations (music by local artists that is similar to music that the human already listens to.)
My students, Paul Gagliano & Griffin Homan, my colleague Venkat Govindarajan set out explore whether LLMs, like ChatGPT, can be used to first generate a natural-language listening (NL) profiles (short descriptions of a person’s music taste) that is meaningful, compact, and easy-to-comprehend. Then, using only an NL profile, can the LLM recommend music artists rather then relying on the list of favorite artists?
Our goal is to make music recommendations more interpretable (easy to understand) and steerable (so users can adjust them in plain language). But before we can get to these two important human-centered concepts, we first needed to figure out how accurate this LLM-based recommender systems is with modern commercial (GPT-o4-Mini) and open-source (Gemma 3 4B IT) LLMs.
What we did
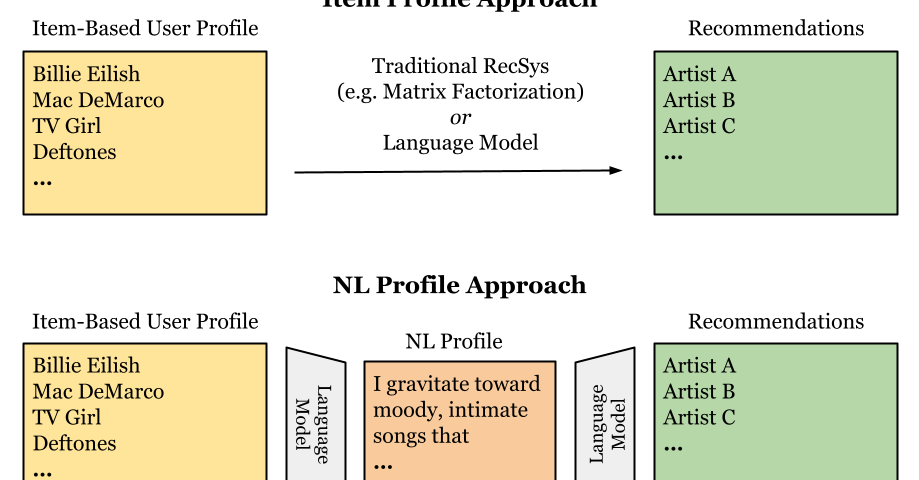
We used real human data from 192 users of Localify.org, our platform for discovering local artists. For each human, we split their favorite artists into “seed” (used for the system to learn from) and “test” (used to check whether the system could correctly recommend them). We compared three approaches:
- Traditional algorithm (matrix factorization) – our baseline.
- Direct use of LLMs – feeding the model a list of seed artists.
- Natural-language profiles with LLMs – asking the model to describe a user’s taste in words, then using that description to make recommendations.
We found that
What we found
- The traditional method performed best (AUC score ~0.82).
- LLM methods worked but were somewhat less accuracte (AUC ~0.75–0.77).
- Natural-language profiles: Using NL Profiles didn’t hurt accuracy, but it also didn’t significantly improve performance compared to giving LLMs the artist list directly.
- Prompt engineering (experimenting with how we wrote instructions for the LLM) made the profiles more readable but did not produce large accuracy gains.
- Popularity bias: Our LLM-based recommendations leaned heavily toward more popular artists. When users liked mainstream music, the recommendations were accurate; when users liked more obscure artists, accuracy dropped.
The main takeaway is that using LLMs out-of-the-box (no training) are not yet as accurate as traditional recommender systems for our artist recommendation task, but they offer something new: explainable, editable profiles that people can read and modify. This capability could improve user trust and make recommendation systems more interactive while also creating opportunities to highlight local or niche music if we can address popularity bias.
Looking ahead, we want to combine LLMs with traditional systems (hybrid approaches), fine-tune models to improve accuracy, and run user studies to test how people actually interact with editable language-based profiles.
You can read more about our study in our workshop paper:
Using Language Models for Music Recommendations with Natural-Language Profiles (slides)
Paul Gagliano, Griffin Homan, Douglas Turnbull, Venkata S Govindarajan
Music Recommender System Workshop (MuRS)
ACM Conference on Recommender Systems
Prague, September 2025